We begin with some mathematical wisdom: “It is sometimes easier to solve a problem by embedding it within a larger class of problems and then solving the larger class all at once.”
A CALCULUS EXAMPLE. Suppose we wish to calculate the value of the integral
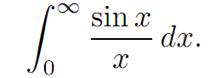
This is pretty hard to do directly, so let us as follows add a parameter α into the integral:

where we integrated by parts twice to find the last equality. Consequently
I(α) = −arctan α + C,
and we must compute the constant C. To do so, observe that
0 = I(∞) = −arctan(∞) + C = −π/2+ C,
and so C = π/2 . Hence I(α) = −arctan α + π/2 , and consequently
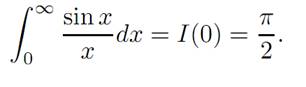
We want to adapt some version of this idea to the vastly more complicated setting of control theory. For this, fix a terminal time T > 0 and then look at the controlled dynamics
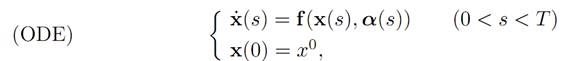
with the associated payoff functional
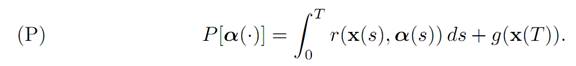
We embed this into a larger family of similar problems, by varying the starting times and starting points:
 (1.1)
(1.1)
With
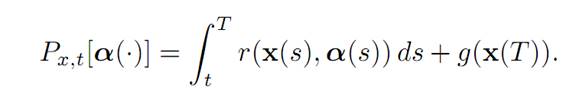 (1.2)
(1.2)
Consider the above problems for all choices of starting times 0 ≤ t ≤ T and all initial points x ∈ Rn.
DEFINITION. For x ∈ Rn, 0 ≤ t ≤ T, define the value function v(x, t) to be the greatest payoff possible if we start at x ∈ Rn at time t. In other words,
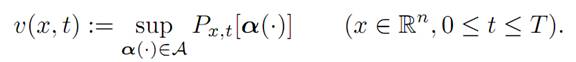 (1.3)
(1.3)
Notice then that
(1.4) v(x, T) = g(x) (x ∈ Rn).
1.2 DERIVATION OF HAMILTON-JACOBI-BELLMAN EQUATION.
Our first task is to show that the value function v satisfies a certain nonlinear partial differential equation.
Our derivation will be based upon the reasonable principle that “it’s better to be smart from the beginning, than to be stupid for a time and then become smart”.
We want to convert this philosophy of life into mathematics.
To simplify, we hereafter suppose that the set A of control parameter values is compact.
THEOREM 1.2 DERIVATION OF HAMILTON-JACOBI-BELLMAN EQUATION.
Our first task is to show that the value function v satisfies a certain nonlinear partial differential equation.
Our derivation will be based upon the reasonable principle that “it’s better to be smart from the beginning, than to be stupid for a time and then become smart”.
We want to convert this philosophy of life into mathematics.
To simplify, we hereafter suppose that the set A of control parameter values is compact.
THEOREM 1.1 (HAMILTON-JACOBI-BELLMAN EQUATION). Assume that the value function v is a C1 function of the variables (x, t). Then v solves the nonlinear partial differential equation1.1 (HAMILTON-JACOBI-BELLMAN EQUATION). Assume that the value function v is a C1 function of the variables (x, t). Then v solves the nonlinear partial differential equation
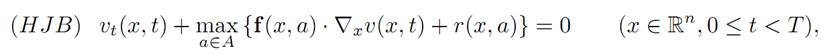
with the terminal condition
v(x, T) = g(x) (x ∈ Rn).
REMARK.We call (HJB) the Hamilton–Jacobi–Bellman equation, and can rewrite it as
(HJB) vt(x, t) + H(x,∇xv) = 0 (x ∈ Rn, 0 ≤ t < T),
for the partial differential equations Hamiltonian
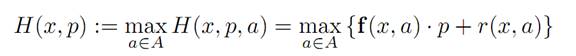
where x, p ∈ Rn.
Proof. 1. Let x ∈ Rn, 0 ≤ t < T and let h > 0 be given. As always
A = {α(.) : [0,∞) → A measurable}.
Pick any parameter a ∈ A and use the constant control
α(.) ≡ a
for times t ≤ s ≤ t + h. The dynamics then arrive at the point x(t + h), where t + h < T. Suppose now a time t + h, we switch to an optimal control and use it for the remaining times t + h ≤ s ≤ T.
What is the payoff of this procedure? Now for times t ≤ s ≤ t + h, we have
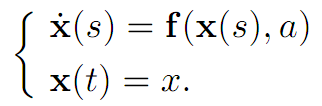
The payoff for this time period is
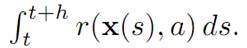
Furthermore, the payoff incurred from time t + h to T is v(x(t + h), t + h), according to the definition of the payoff function v. Hence the total payoff is

But the greatest possible payoff if we start from (x, t) is v(x, t). Therefore
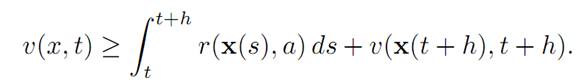 (1.5)
(1.5)
2. We now want to convert this inequality into a differential form. So we rearrange (1.5) and divide by h > 0:
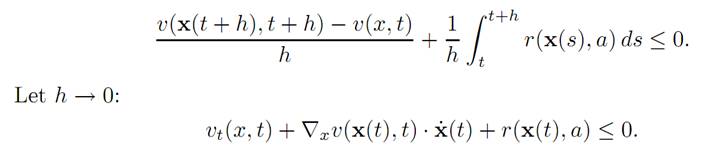
But x(.) solves the ODE
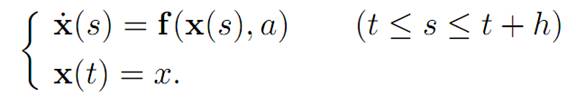
Employ this above, to discover:
vt(x, t) + f (x, a) .∇xv(x, t) + r(x, a) ≤ 0.
This inequality holds for all control parameters a ∈ A, and consequently
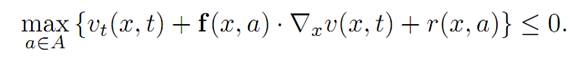 (1.6)
(1.6)
3. We next demonstrate that in fact the maximum above equals zero. To see this, suppose α∗(.), x∗(.) were optimal for the problem above. Let us utilize the optimal control α∗(.) for t ≤ s ≤ t + h. The payoff is
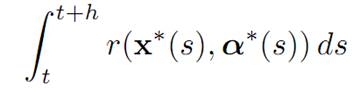
and the remaining payoff is v(x∗(t + h), t + h). Consequently, the total payoff is
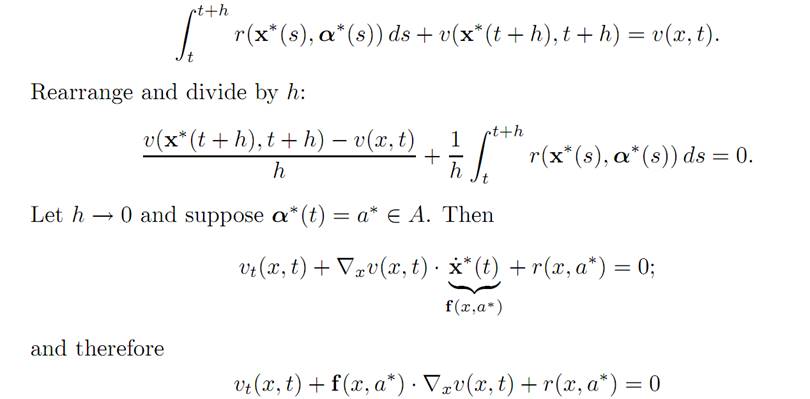
for some parameter value a∗ ∈ A. This proves (HJB).
1.3 THE DYNAMIC PROGRAMMING METHOD
Here is how to use the dynamic programming method to design optimal controls:
Step 1: Solve the Hamilton–Jacobi–Bellman equation, and thereby compute the value function v.
Step 2: Use the value function v and the Hamilton–Jacobi–Bellman PDE to design an optimal feedback control α∗(.), as follows. Define for each point x ∈ Rn and each time 0 ≤ t ≤ T, α(x, t) = a ∈ A
to be a parameter value where the maximum in (HJB) is attained. In other words, we select α(x, t) so that
vt(x, t) + f (x,α(x, t)) . ∇xv(x, t) + r(x,α(x, t)) = 0.
Next we solve the following ODE, assuming α(., t) is sufficiently regular to let us do so:

Finally, define the feedback control
(1.7) α∗ (s) := α(x∗ (s), s).
In summary, we design the optimal control this way: If the state of system is x at time t, use the control which at time t takes on the parameter value a ∈ A such that the minimum in (HJB) is obtained.
We demonstrate next that this construction does indeed provide us with an optimal control.
THEOREM1.2 (VERIFICATION OF OPTIMALITY). The control α∗(.) defined by the construction (1.7) is optimal.
Proof. We have
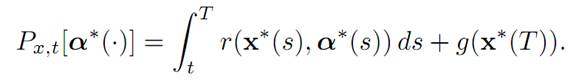
Furthermore according to the definition (1.7) of α(.):
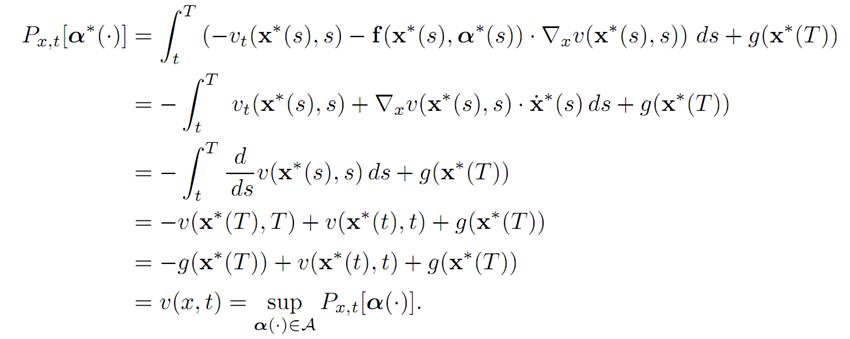
That is,

and so α∗(.) is optimal, as asserted.
References
[B-CD] M. Bardi and I. Capuzzo-Dolcetta, Optimal Control and Viscosity Solutions of Hamilton-Jacobi-Bellman Equations, Birkhauser, 1997.
[B-J] N. Barron and R. Jensen, The Pontryagin maximum principle from dynamic programming and viscosity solutions to first-order partial differential equations, Transactions AMS 298 (1986), 635–641.
[C1] F. Clarke, Optimization and Nonsmooth Analysis, Wiley-Interscience, 1983.
[C2] F. Clarke, Methods of Dynamic and Nonsmooth Optimization, CBMS-NSF Regional Conference Series in Applied Mathematics, SIAM, 1989.
[Cr] B. D. Craven, Control and Optimization, Chapman & Hall, 1995.
[E] L. C. Evans, An Introduction to Stochastic Differential Equations, lecture notes avail-able at http://math.berkeley.edu/˜ evans/SDE.course.pdf.
[F-R] W. Fleming and R. Rishel, Deterministic and Stochastic Optimal Control, Springer, 1975.
[F-S] W. Fleming and M. Soner, Controlled Markov Processes and Viscosity Solutions, Springer, 1993.
[H] L. Hocking, Optimal Control: An Introduction to the Theory with Applications, OxfordUniversity Press, 1991.
[I] R. Isaacs, Differential Games: A mathematical theory with applications to warfare and pursuit, control and optimization, Wiley, 1965 (reprinted by Dover in 1999).
[K] G. Knowles, An Introduction to Applied Optimal Control, Academic Press, 1981.
[Kr] N. V. Krylov, Controlled Diffusion Processes, Springer, 1980.
[L-M] E. B. Lee and L. Markus, Foundations of Optimal Control Theory, Wiley, 1967.
[L] J. Lewin, Differential Games: Theory and methods for solving game problems with singular surfaces, Springer, 1994.
[M-S] J. Macki and A. Strauss, Introduction to Optimal Control Theory, Springer, 1982.
[O] B. K. Oksendal, Stochastic Differential Equations: An Introduction with Applications, 4th ed., Springer, 1995.
[O-W] G. Oster and E. O. Wilson, Caste and Ecology in Social Insects, Princeton UniversityPress.
[P-B-G-M] L. S. Pontryagin, V. G. Boltyanski, R. S. Gamkrelidze and E. F. Mishchenko, The Mathematical Theory of Optimal Processes, Interscience, 1962.
[T] William J. Terrell, Some fundamental control theory I: Controllability, observability, and duality, American Math Monthly 106 (1999), 705–719.





















